Web scraping : guide méthodique, technique et légal
Le web scraping est une compétence fondamentale pour quiconque souhaite exploiter la valeur immense des données publiques disponibles en ligne. Cet article pédagogique vous explique en détail ce qu'est le web scraping, comment le mettre en œuvre techniquement et légalement, ses applications concrètes en entreprise et comment l'intelligence artificielle redéfinit radicalement cette discipline. Nous abordons également les outils émergents comme Google Disco et Perplexity Comet qui démocratisent l'accès à ces techniques. Notre objectif est de vous fournir un cadre de connaissance opérationnel, de la théorie à la pratique avancée, en insistant sur les bonnes pratiques et l'éthique.
- Le web scraping transforme le web en base de données exploitable grâce à l’automatisation.
- Le risque juridique principal vient des CGU et du RGPD, pas du scraping “en soi”.
- L’IA rend les extracteurs plus adaptatifs et fait évoluer la compétence vers le prompt et l’orchestration.
Qu'est-ce que le web scraping ? définition, mécanismes et cas d'usage fondamentaux
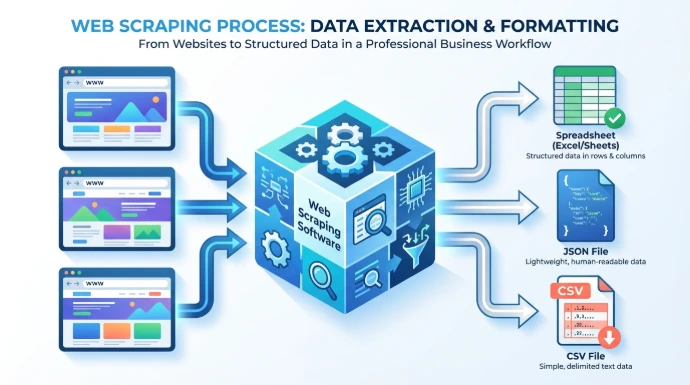
Le web scraping est la technique d'extraction automatisée de données structurées à partir de sites web publics. On l'appelle aussi moissonnage du web. Concrètement, il s'agit d'utiliser un programme, souvent appelé scraper ou robot, pour simuler la navigation d'un humain, télécharger le code source des pages, analyser ce contenu et en extraire des informations spécifiques pour les stocker dans un format utilisable comme un tableau CSV, une base de données ou une feuille de calcul.
La puissance du web scraping réside dans son automatisation et sa capacité à traiter des volumes de données massifs, rendant possible en quelques minutes ce qui requerrait des centaines d'heures de copier-coller manuel. C'est un outil indispensable pour la veille concurrentielle, la recherche académique, l'agrégation de contenu et l'alimentation de systèmes d'information.
Prenons un exemple concret. Imaginez que vous deviez suivre les prix de 1000 produits sur 10 sites e-commerce différents chaque jour. Manuellement, cette tâche est impossible. Un scraper peut être programmé pour visiter chaque page produit, localiser la balise HTML contenant le prix, extraire cette valeur numérique et l'enregistrer avec la date et le nom du produit. Le processus fondamental suit toujours trois étapes. La première étape est la requête HTTP. Le script envoie une requête au serveur du site cible, exactement comme le fait votre navigateur lorsque vous tapez une URL. La seconde étape est le parsing. Une fois le code HTML reçu, le script l'analyse pour comprendre sa structure, identifiant les balises, les classes CSS et les identifiants qui encapsulent les données désirées. La troisième étape est l'extraction et le stockage. Le script sélectionne les éléments pertinents, nettoie les données et les sauvegarde dans un format structuré.
Contrairement à une idée reçue, le web scraping ne se limite pas au texte. Il peut extraire des images, des fichiers PDF, des liens, des métadonnées et bien plus. Les outils de base comme les bibliothèques Requests pour la récupération et BeautifulSoup pour l'analyse en Python ont démocratisé l'accès à cette technologie. Ils permettent à des non-spécialistes de créer des extracteurs de données robustes. Cette approche transforme le web, vaste collection de documents destinés à la lecture humaine, en une gigantesque base de données interrogeable et exploitable par des machines.
Le web scraping s'apparente à la lecture d'une page web par un programme. Le programme doit d'abord demander la page, puis la comprendre. Comprendre une page web, pour une machine, c'est analyser son code HTML. Le HTML est un langage de balises qui structure le contenu. Une balise titre est entourée de <h1>, un paragraphe de <p>, et un prix pourrait être dans un élément <span class="prix">29,99 €</span>. Le scraper utilise ces indices structurels pour naviguer dans le document et repérer l'information cible. Cette méthode est à la fois simple et puissante, car elle repose sur la logique inhérente à la construction des sites.
Comment faire du web scraping avec Python ? un tutoriel technique pas à pas
Python est le langage de référence pour le web scraping en raison de sa simplicité de syntaxe et de l'écosystème riche de bibliothèques dédiées. Pour débuter, vous n'avez besoin que de deux bibliothèques principales. Installez-les via pip avec la commande pip install requests beautifulsoup4. Requests gère la communication HTTP, c'est-à-dire le téléchargement des pages. BeautifulSoup se charge de l'analyse syntaxique du HTML, permettant de naviguer dans l'arborescence des balises et d'extraire les données.
Voici le squelette d'un script basique de web scraping. Nous allons le détailler ligne par ligne.
python
import requests
from bs4 import BeautifulSoup
url = 'https://exemple.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
titres = soup.find_all('h2', class_='titre-article')
for titre in titres:
print(titre.text.strip())La première ligne importe la bibliothèque requests. La seconde importe BeautifulSoup. Nous définissons ensuite l'URL cible. La définition des en-têtes HTTP, notamment du User-Agent, est cruciale. Certains sites bloquent les requêtes qui ne viennent pas d'un navigateur reconnu. L'utilisation d'un User-Agent standard comme celui de Mozilla Firefox permet de contourner cette première ligne de défense. La fonction requests.get() envoie la requête et stocke la réponse dans l'objet response. Son attribut .text contient le code HTML de la page.
Nous passons ce HTML à BeautifulSoup en spécifiant le parser à utiliser, ici html.parser. L'objet soup qui en résulte est une représentation structurée de la page sur laquelle nous pouvons effectuer des recherches. La méthode find_all() est l'outil principal d'extraction. Elle retourne une liste de tous les éléments correspondant aux critères. Ici, nous cherchons toutes les balises <h2> dont la classe CSS est titre-article. Nous parcourons ensuite cette liste avec une boucle for et affichons le texte de chaque titre après l'avoir nettoyé des espaces superflus avec .strip().
La sélection des éléments est la compétence centrale. Pour la maîtriser, vous devez inspecter le code source des pages que vous ciblez. Ouvrez les outils de développement de votre navigateur avec F12. Utilisez l'outil d'inspection pour cliquer sur l'élément dont vous voulez extraire la donnée. Le navigateur vous montrera la balise HTML exacte, ses classes et ses identifiants. Vous pouvez utiliser des sélecteurs CSS plus puissants avec BeautifulSoup via la méthode select(). Par exemple, soup.select('div.produit > a.lien-principal') sélectionnera tous les liens de classe lien-principal situés directement dans un div de classe produit.
La gestion de la pagination est un challenge courant. Un site liste ses produits sur plusieurs pages. Votre script doit être capable de passer de l'une à l'autre automatiquement. La stratégie consiste souvent à analyser le lien "Suivant" présent en bas de page. Vous pouvez mettre votre code d'extraction dans une boucle while qui continue tant qu'un tel lien existe. À chaque itération, vous suivez ce lien, extrayez les données de la nouvelle page, puis recherchez à nouveau le lien "Suivant". Il est impératif d'ajouter des délais entre les requêtes avec time.sleep(2) par exemple. Cela réduit la charge sur le serveur cible et diminue les risques d'être bloqué pour requêtes trop agressives.
Pour les sites dynamiques qui chargent leur contenu avec JavaScript, Requests et BeautifulSoup ne suffisent plus. Elles ne voient que le HTML initial, sans le code exécuté par le navigateur. Dans ce cas, il faut utiliser des outils comme Selenium ou Playwright. Ils pilotent un vrai navigateur web, permettent d'attendre le chargement des éléments, de cliquer sur des boutons et d'exécuter du JavaScript. L'extraction se fait ensuite de manière similaire. Ces outils sont plus lourds mais essentiels pour une grande partie du web moderne.
L'export des données est la finalité. La bibliothèque Pandas est parfaite pour cela. Vous pouvez stocker vos données extraites dans une liste de dictionnaires, puis créer un DataFrame Pandas et l'exporter en CSV, Excel ou JSON.
python
import pandas as pd
data = []
for element in elements_extraits:
data.append({'nom': element.nom, 'prix': element.prix})
df = pd.DataFrame(data)
df.to_csv('donnees.csv', index=False, encoding='utf-8-sig')Commencez par vous entraîner sur des sites simples et prévus pour cela, comme les pages de Wikipedia. Évitez de scraper des sites commerciaux sans réfléchir aux conditions d'utilisation. Testez vos scripts à petite échelle avant de les lancer sur des milliers de pages. La robustesse d'un scraper vient de sa capacité à gérer les erreurs. Utilisez des blocs try...except pour gérer les timeouts, les éléments manquants ou les changements de structure.
Outils populaires pour le web scraping : du no-code aux frameworks d'entreprise
Le paysage des outils de web scraping est vaste, allant des solutions graphiques sans code aux frameworks complexes pour ingénieurs. Le choix dépend de vos compétences techniques, du volume de données, de la complexité des sites cibles et de votre budget.
Pour les débutants et les projets rapides, les outils no-code sont une excellente porte d'entrée. Octoparse et ParseHub proposent une interface visuelle de type glisser-déposer. Vous naviguez sur le site dans un navigateur intégré et cliquez sur les éléments à extraire. L'outil apprend le motif et peut le reproduire sur plusieurs pages. Ces solutions gèrent souvent le JavaScript, la pagination et l'export. Leur principal avantage est la rapidité de mise en route, sans écrire une ligne de code. L'inconvénient majeur est leur limite en volume pour les versions gratuites et leur manque de flexibilité pour des scénarios complexes. Ils sont parfaits pour des projets ponctuels de veille ou pour des équipes commerciales ou marketing.
Du côté des solutions par code, Python reste le roi. Pour des projets plus sérieux et personnalisables, les frameworks comme Scrapy sont incontournables. Scrapy n'est pas qu'une bibliothèque, c'est un framework complet conçu spécifiquement pour le web scraping à grande échelle. Il gère nativement la concurrence pour envoyer plusieurs requêtes en parallèle, un système de pipeline pour traiter les données à la volée, des middlewares pour gérer les proxies et les user-agents, et une architecture robuste. Sa courbe d'apprentissage est plus raide que BeautifulSoup, mais la productivité gagnée sur des projets d'envergure est immense. Il est particulièrement adapté au crawling, c'est-à-dire à la navigation systématique à travers de nombreux liens et domaines.
Pour le JavaScript, Puppeteer et Playwright sont les outils dominants pour le scraping de sites dynamiques. Puppeteer, développé par l'équipe Chrome, et son successeur Playwright, de Microsoft, qui supporte Chrome, Firefox et WebKit, permettent un contrôle très fin d'un navigateheadless. Ils peuvent générer des captures d'écran, simuler des interactions au clavier et à la souris, et exécuter n'importe quel code JavaScript sur la page. Ils sont indispensables pour scraper des applications web modernes construites avec React, Vue.js ou Angular. Leur inconvénient est leur consommation de ressources, car ils nécessitent l'exécution d'un moteur de navigateur complet.
Les services API comme ScrapingBee ou ScraperAPI offrent une troisième voie. Vous leur envoyez l'URL à scraper et ils vous retournent le HTML, en gérant à votre place tous les problèmes techniques : rotation de proxies pour éviter les IP bannies, rendu JavaScript, gestion des CAPTCHAs, respect de robots.txt. Ces services sont payants, généralement à la requête, mais ils externalisent la complexité opérationnelle. Ils sont idéaux pour les entreprises qui ont besoin de données fiables sans vouloir maintenir une infrastructure de scraping interne.
Les extensions navigateur comme Web Scraper.io se placent entre le no-code et le code. C'est une extension Chrome qui permet de définir des sélecteurs visuellement et de créer des plans de navigation. Les données sont extraites localement dans votre navigateur puis exportables. C'est très pratique pour des extractions légères et rapides, mais peu adapté à l'automatisation et aux volumes importants.
Le tableau suivant résume les choix possibles :
Catégorie Outil Avantages Inconvénients Prix
No-code Octoparse Interface drag-and-drop, support JS, rapide Limité en scale, gratuit freemium Freemium
No-code ParseHub Cloud, point-and-click, puissant Courbe d'apprentissage, coût à l'échelle Freemium
Code (Python) Scrapy Scalable, architecture solide, idéal crawling Complexe pour débutants Gratuit
Code (JS) Playwright Multi-navigateurs, interactions réalistes Consommation ressources, plus complexe Gratuit
API Service ScrapingBee Gère proxies/JS/CAPTCHAs, simple d'usage Coût par requête, dépendance externe Payant
Extension WebScraper.io Intégré à Chrome, très simple Manuel, pas pour volumes ou automatisation FreemiumAvant de choisir, consultez toujours le fichier robots.txt du site cible, accessible à l'adresse https://nomdusite.com/robots.txt. Ce fichier indique les parties du site que les propriétaires autorisent ou interdisent explicitement aux robots d'explorer. Le respect de robots.txt est une première marque d'éthique et peut vous éviter des ennuis juridiques. Cependant, notez que ce n'est pas un cadre légal contraignant en soi, mais une indication des souhaits du webmaster.
Légalité du web scraping en France et en Europe : cadre juridique et bonnes pratiques
La question juridique est probablement la plus critique et la plus complexe autour du web scraping. Une idée fausse très répandue est que le web scraping est illégal. En réalité, dans sa forme la plus basique, il ne l'est pas intrinsèquement en Europe. L'extraction de données publiquement accessibles sur internet est, en principe, licite. Le droit français et européen reconnaît une certaine liberté d'exploitation des informations disponibles publiquement, notamment à des fins de recherche, d'innovation ou d'analyse.
La base légale française se trouve notamment dans le Code de la propriété intellectuelle, article L.342-3. Il stipule que la base de données constituée par un site web peut être protégée par un droit sui generis si son obtention, sa vérification ou sa présentation représente un investissement financier, matériel ou humain substantiel. Toutefois, l'extraction d'une partie non substantielle de son contenu, souvent à des fins privées ou de recherche, est généralement autorisée. C'est une zone grise où la notion de "partie substantielle" est subjective et s'apprécie au cas par cas.
Le premier risque majeur provient de la violation des Conditions Générales d'Utilisation. Beaucoup de sites incluent une clause dans leurs CGU interdisant explicitement le scraping, l'automatisation ou l'utilisation de robots. En utilisant le site, vous acceptez contractuellement ces conditions. Les techniques de contournement de ces interdictions, comme l'usurpation d'identité via le User-Agent ou l'utilisation de proxies pour masquer son IP, peuvent aggraver la situation en constituant potentiellement un accès frauduleux à un système informatique, réprimé par l'article 323-1 du Code pénal, avec des peines pouvant aller jusqu'à cinq ans d'emprisonnement et 300 000 euros d'amende.
Le deuxième risque, et le plus lourd de conséquences aujourd'hui, est lié au Règlement Général sur la Protection des Données. Le RGPD s'applique dès lors que vous traitez des données à caractère personnel, c'est-à-dire toute information se rapportant à une personne physique identifiée ou identifiable. Un nom, une adresse email, un numéro de téléphone, mais aussi une adresse IP ou un identifiant de cookie sont des données personnelles. Si votre projet de scraping implique de collecter de telles données, vous devez vous conformer au RGPD.
Cela signifie que vous devez identifier une base légale pour votre traitement. La base la plus couramment invoquée pour le scraping à des fins professionnelles est l'intérêt légitime. Vous devez démontrer que votre intérêt légitime (par exemple, une analyse de marché) n'est pas surpassé par les droits et libertés de la personne concernée. Vous devez également informer les personnes, via une politique de confidentialité, que vous collectez leurs données et comment. En pratique, pour le scraping de profils publics LinkedIn à grande échelle, la CNIL a déjà sanctionné des entreprises, comme dans une décision de 2020 avec une amende de 20 000 euros. La jurisprudence européenne, avec l'arrêt "hiQ Labs c. LinkedIn", a cependant reconnu un certain droit au scraping de données publiques, même contre l'avis du site, au nom de la libre concurrence et de l'intérêt public, mais ce cadre évolue constamment.
Les bonnes pratiques sont donc impératives. Premièrement, limitez le taux de requêtes pour ne pas surcharger les serveurs. Utilisez des délais entre chaque requête. Deuxièmement, identifiez-vous clairement dans votre User-Agent avec une adresse email de contact. Troisièmement, ne collectez que le strict nécessaire et anonymisez les données personnelles dès que possible. Quatrièmement, respectez le champ robots.txt. Enfin, pour tout projet commercial d'envergure, consultez un juriste spécialisé en droit du numérique et en propriété intellectuelle. Cette consultation est un investissement nécessaire pour sécuriser vos activités, surtout si vous envisagez de créer une base de données à des fins de prosopographie ou de pricing dynamique.
Applications pratiques du web scraping : cas concrets sectoriels et création de valeur
Le web scraping n'est pas une fin en soi, c'est un moyen au service de la stratégie et de l'opérationnel. Sa valeur se mesure à l'impact qu'il a sur les processus métier, la prise de décision et la rentabilité. Examinons des applications concrètes dans différents secteurs.
Dans l'e-commerce et la vente au détail, le web scraping est un pilier de la stratégie de pricing dynamique. Des entreprises comme camelcamelcamel scannent en permanence les prix de millions de produits sur Amazon pour tracer leur historique et alerter sur les baisses. Les grands retailers utilisent des scrapers maison pour surveiller les prix de leurs concurrents directs, plusieurs fois par jour. Cette intelligence permet d'ajuster ses propres prix en temps quasi réel pour rester compétitif sans sacrifier la marge. On estime qu'une stratégie de pricing optimisée par le scraping peut augmenter les marges de 5 à 20%. Au-delà du prix, on peut scraper les descriptions produits, les images, les avis clients et le stock pour enrichir son propre catalogue ou analyser la satisfaction client.
Dans le domaine du recrutement et des ressources humaines, le scraping transforme la chasse de talents. Les plateformes comme Indeed, LinkedIn et les sites carrières des entreprises regorgent de données structurées sur les offres d'emploi : intitulé du poste, compétences requises, localisation, fourchette salariale parfois. Un scraper peut agréger ces offres par métier, par région, par niveau d'expérience. Pour un cabinet de recrutement, cela permet de cartographier le marché, d'identifier les compétences les plus demandées et de conseiller efficacement ses candidats. Pour une grande entreprise, cela permet une analyse de la concurrence sur les packages de rémunération et les avantages.
L'industrie du voyage est probablement l'une des plus transformées par ces techniques. Les agrégateurs comme Kayak, Skyscanner ou Google Flights fonctionnent essentiellement grâce à des partenariats et du scraping avancé pour collecter les prix des billets d'avion, des chambres d'hôtel et des locations de voiture depuis des centaines de sources. Des outils plus spécialisés permettent aux agences de voyage de créer des alertes personnalisées pour leurs clients ou d'analyser les tendances tarifaires sur des destinations précises.
Dans les médias et le sport, le scraping permet de créer des agrégateurs d'actualités ou de scores. Des sites comme Transfermarkt, référence du football, construisent leur base de données colossale sur les joueurs, les transferts et les valeurs de marché grâce à une collecte systématique d'informations publiques. Les sociétés de trading sportif utilisent le scraping en temps réel sur les sites officiels pour alimenter leurs modèles de prédiction.
Pour les systèmes d'information d'entreprise comme les ERP, le web scraping est un levier puissant d'automatisation et d'enrichissement. Prenons l'exemple d'Odoo, populaire en Bretagne et ailleurs. Une entreprise manufacturière peut scraper les catalogues de ses fournisseurs pour mettre à jour automatiquement les prix et les références dans son ERP. Une entreprise de distribution peut enrichir sa base clients en collectant des informations publiques sur les sites de ses prospects. Une entreprise agroalimentaire peut surveiller les prix des matières premières sur les marchés en ligne. L'intégration se fait via les APIs Python d'Odoo, créant un flux de données entrant automatisé qui élimine les saisies manuelles, sources d'erreur et de perte de temps.
La valeur finale est toujours la même. Le web scraping automatise la veille, transforme des données brutes et éparses en information actionnable, et permet une prise de décision plus rapide et plus éclairée. Il réduit les coûts opérationnels et peut générer des gains de revenus significatifs. C'est un multiplicateur de force pour les entreprises qui savent l'utiliser de manière éthique et efficace.
L'avenir du web scraping avec l'intelligence artificielle : des agents autonomes et auto-adaptatifs
L'arrivée de l'intelligence artificielle générative et des grands modèles de langage est en train de provoquer une disruption majeure dans le domaine du web scraping. La limite traditionnelle était la rigidité du code. Un scraper écrit pour une page spécifique casse dès que la structure HTML change. La maintenance était coûteuse. L'IA change la donne en introduisant la compréhension sémantique et l'adaptabilité.
Le concept émergent est celui du MCP, ou Model Context Protocol. Il s'agit de fournir à un grand modèle de langage, comme GPT-4, le contexte d'une page web et de lui demander d'extraire des informations via des instructions en langage naturel. Au lieu d'écrire du code avec des sélecteurs CSS complexes comme div.product-price > span.value, vous donnez un prompt : "Extrais tous les prix des produits et leurs noms sur cette page." Le modèle comprend la sémantique de la page, identifie ce qu'est un prix et un nom de produit, et retourne les données structurées. Des outils comme ScrapeGraphAI incarnent cette approche. Ils utilisent des LLMs pour interpréter la page, générer le code d'extraction adapté et même s'ajuster automatiquement à de légers changements de mise en page.
Les tendances pour 2026 et au-delà se dessinent clairement. Nous allons voir l'émergence d'agents de scraping autonomes et self-healing. Ces agents recevront une mission en langage naturel, comme "Surveille l'évolution du prix de ce modèle de vélo sur ces 5 sites e-commerce chaque jour et envoie-moi un rapport hebdomadaire." L'agent planifiera lui-même les exécutions, détectera les changements de structure du site, ajustera sa stratégie d'extraction et vous alertera en cas de problème. La maintenance humaine sera réduite au minimum.
Les services cloud évoluent également. Les APIs de scraping traditionnelles vont intégrer des modules IA pour le rendu JavaScript, la résolution de CAPTCHAs complexes via la vision par ordinateur, et la rotation intelligente des proxies pour imiter des comportements humains réels et contourner les systèmes de détection de plus en plus sophistiqués.
La dimension éthique et régulatoire sera aussi transformée par l'IA. Nous pourrions voir l'apparition de fichiers robots.txt enrichis, interprétables par les IA, détaillant non seulement ce qui est interdit mais aussi les conditions d'usage des données. L'EU AI Act, le règlement européen sur l'intelligence artificielle, classera probablement certains systèmes de scraping IA à grande échelle et intrusifs comme à haut risque, imposant des obligations de transparence et de conformité renforcées.
Le défi majeur sera la course aux armements entre les scrapers IA et les systèmes anti-bot IA. Les sites chercheront à protéger leurs données avec des défenses adaptatives qui détectent les patterns non-humains, même sophistiqués. L'équilibre entre l'accès légitime à l'information publique et la protection de la propriété intellectuelle et de la vie privée se jouera sur ce terrain technologique. Pour l'utilisateur final, cette évolution signifie une démocratisation encore plus grande. La barrière technique du code disparaît. L'extraction de données web deviendra une compétence accessible à tout professionnel sachant formuler clairement son besoin.
Google Disco et Perplexity Comet : Les navigateurs agentiques, des game-changers no-code
Deux produits récents illustrent parfaitement la fusion entre le web scraping, la navigation et l'intelligence artificielle générative. Ils préfigurent l'avenir de l'interaction avec le web pour la collecte d'information.
Google Disco est un projet expérimental issu de Google Labs, révélé fin 2025. Il s'agit d'un navigateur, ou d'une extension de navigateur, propulsé par Gemini, le modèle d'IA de Google. Son principe révolutionnaire est simple. Vous ouvrez plusieurs onglets sur des sujets connexes, par exemple des pages de comparateurs de vols, des blogs de voyage et des sites météorologiques pour une destination. Disco analyse le contenu de tous ces onglets ouverts simultanément. Ensuite, via une interface conversationnelle, il vous propose de générer des "GenTabs". Ces GenTabs sont des tableaux de bord personnalisés qui extraient et croisent automatiquement les données de vos onglets sources. Par exemple, un GenTab "Planificateur de voyage" pourrait extraire les prix des billets d'un onglet, les avis sur les hôtels d'un autre et les prévisions météo d'un troisième, pour les présenter dans un seul tableau synthétique, exportable. L'implication est énorme. L'utilisateur n'a plus besoin de savoir quoi scraper ni comment. Il navigue normalement, et l'IA déduit son intention et lui propose des synthèses actionnables. L'intégration potentielle dans Chrome en ferait un outil d'une puissance inédite pour les chercheurs, les analystes et les consultants.
Perplexity Comet, de son côté, est présenté comme un "navigateur agentique". C'est une application à part entière qui repense la navigation. Vous ne surfez plus, vous donnez une mission. Le prompt est roi. Vous tapez : "Scrape les 10 premiers t-shirts pour homme sur Amazon, avec leur prix, leur note moyenne et le nombre d'avis, et exporte-les dans un fichier CSV." Comet lance alors un navigateheadless, exécute la recherche sur Amazon, parcourt les pages, extrait les données demandées, les structure et télécharge le fichier CSV sur votre ordinateur. Tout cela sans que vous n'ayez jamais vu la page Amazon. Il gère la navigation, le JavaScript, la pagination, les pop-ups. La version Pro, accessible via un système de referral, offre plus de puissance et de requêtes. Pour un consultant qui doit régulièrement faire de la veille produit ou du lead generation, c'est un gain de temps phénoménal. Pour l'intégration dans un ERP comme Odoo, on imagine très bien des agents Comet programmés pour surveiller quotidiennement les prix de fournisseurs ou les fiches produits de concurrents, et mettre à jour automatiquement les bases de données internes via API.
Ces outils ne sont pas de simples améliorations. Ce sont des changements de paradigme. Ils démocratisent l'accès à la puissance du web scraping en le rendant totalement no-code et conversationnel. Le métier évolue du développement de scripts techniques vers la conception de prompts précis et la gestion de workflows d'agents intelligents. Pour les entreprises, en particulier les PME qui n'ont pas de département technique dédié, c'est une opportunité immense d'automatiser leur veille et d'enrichir leurs systèmes d'information à un coût marginal très faible. Le rôle du consultant ou de l'intégrateur devient alors d'identifier les flux de données critiques, de concevoir les prompts et les workflows adaptés, et d'assurer l'intégration fluide avec les outils métier comme Odoo.
Bonnes pratiques, perspectives et conclusion pour votre stratégie
Pour conclure ce guide pédagogique, synthétisons les bonnes pratiques absolues et les perspectives stratégiques, en particulier pour un contexte d'entreprise utilisant des ERP comme Odoo.
Sur le plan éthique et opérationnel, adoptez toujours une approche responsable. Sollicitez le consentement quand c'est possible, surtout pour les données personnelles. Implémentez un rate-limiting strict. Laissez toujours une trace de contact dans vos requêtes. Ne scrapez que ce dont vous avez besoin. Vérifiez la licéité de votre projet avec un expert juridique. Ces précautions ne sont pas des freins, ce sont les fondations d'une pratique durable qui protège votre entreprise de risques majeurs.
Sur le plan technique, adoptez une architecture hybride IA/code. Utilisez les nouveaux outils agentiques comme Google Disco ou Perplexity Comet pour le prototypage rapide, l'exploration et les projets légers. Pour les pipelines de production critiques, volumineux et nécessitant une fiabilité absolue, maintenez une base de code traditionnelle avec Scrapy ou Playwright. L'IA peut alors servir d'outil de résilience, capable de réparer ou de réécrire des parties du code si une structure de site change brutalement.
Concrètement, pour vous, entreprise basée en Bretagne utilisant Odoo, voici un plan d'action. Identifiez les données externes qui auraient le plus d'impact sur votre ERP. Est-ce le prix des matières premières agricoles ou textile que vous achetez ? Est-ce le catalogue produit de vos concurrents pour votre propre boutique en ligne ? Est-ce la liste des entreprises de votre secteur dans votre région pour votre force de vente ? Priorisez une source.
Commencez par un prototype avec un outil no-code IA. Testez la faisabilité de l'extraction. Puis, pour une automatisation robuste, développez un script Python qui scrape ces données périodiquement. Structurez-les dans un DataFrame Pandas. Enfin, utilisez l'API REST ou XML-RPC d'Odoo pour pousser ces données directement dans les modules concernés. Vous pouvez créer des produits, mettre à jour des fiches fournisseurs, ajuster des listes de prix, tout cela sans intervention manuelle.
La clé réside dans la structure et la clarté de votre démarche. Chaque section de votre projet doit répondre à une seule intention. Avant de coder, définissez précisément la question métier. L'outil technique n'est qu'une réponse. En adoptant cette discipline et en exploitant la puissance conjuguée du scraping traditionnel et de l'IA générative, vous transformez le web, océan de données désorganisées, en un actif stratégique structuré et dynamique pour votre entreprise. L'avenir appartient à ceux qui savent non pas seulement collecter des données, mais orchestrer intelligemment leur flux pour éclairer la décision et automatiser l'action.
- Définissez d’abord l’objectif métier, puis choisissez l’outil et l’architecture.
- Prototypage no-code IA pour valider vite, pipeline code pour industrialiser.
- Conformité et éthique : limitation du débit, minimisation des données, vigilance RGPD et CGU.
Web scraping : guide méthodique, technique et légal
Le web scraping est une compétence fondamentale pour quiconque souhaite exploiter la valeur immense des données publiques disponibles en ligne. Cet article pédagogique vous explique en détail ce qu'est le web scraping, comment le mettre en œuvre techniquement et légalement, ses applications concrètes en entreprise et comment l'intelligence artificielle redéfinit radicalement cette discipline. Nous abordons également les outils émergents comme Google Disco et Perplexity Comet qui démocratisent l'accès à ces techniques. Notre objectif est de vous fournir un cadre de connaissance opérationnel, de la théorie à la pratique avancée, en insistant sur les bonnes pratiques et l'éthique.
- Le web scraping transforme le web en base de données exploitable grâce à l’automatisation.
- Le risque juridique principal vient des CGU et du RGPD, pas du scraping “en soi”.
- L’IA rend les extracteurs plus adaptatifs et fait évoluer la compétence vers le prompt et l’orchestration.
Qu'est-ce que le web scraping ? définition, mécanismes et cas d'usage fondamentaux
Le web scraping est la technique d'extraction automatisée de données structurées à partir de sites web publics. On l'appelle aussi moissonnage du web. Concrètement, il s'agit d'utiliser un programme, souvent appelé scraper ou robot, pour simuler la navigation d'un humain, télécharger le code source des pages, analyser ce contenu et en extraire des informations spécifiques pour les stocker dans un format utilisable comme un tableau CSV, une base de données ou une feuille de calcul.
La puissance du web scraping réside dans son automatisation et sa capacité à traiter des volumes de données massifs, rendant possible en quelques minutes ce qui requerrait des centaines d'heures de copier-coller manuel. C'est un outil indispensable pour la veille concurrentielle, la recherche académique, l'agrégation de contenu et l'alimentation de systèmes d'information.
Prenons un exemple concret. Imaginez que vous deviez suivre les prix de 1000 produits sur 10 sites e-commerce différents chaque jour. Manuellement, cette tâche est impossible. Un scraper peut être programmé pour visiter chaque page produit, localiser la balise HTML contenant le prix, extraire cette valeur numérique et l'enregistrer avec la date et le nom du produit. Le processus fondamental suit toujours trois étapes. La première étape est la requête HTTP. Le script envoie une requête au serveur du site cible, exactement comme le fait votre navigateur lorsque vous tapez une URL. La seconde étape est le parsing. Une fois le code HTML reçu, le script l'analyse pour comprendre sa structure, identifiant les balises, les classes CSS et les identifiants qui encapsulent les données désirées. La troisième étape est l'extraction et le stockage. Le script sélectionne les éléments pertinents, nettoie les données et les sauvegarde dans un format structuré.
Contrairement à une idée reçue, le web scraping ne se limite pas au texte. Il peut extraire des images, des fichiers PDF, des liens, des métadonnées et bien plus. Les outils de base comme les bibliothèques Requests pour la récupération et BeautifulSoup pour l'analyse en Python ont démocratisé l'accès à cette technologie. Ils permettent à des non-spécialistes de créer des extracteurs de données robustes. Cette approche transforme le web, vaste collection de documents destinés à la lecture humaine, en une gigantesque base de données interrogeable et exploitable par des machines.
Le web scraping s'apparente à la lecture d'une page web par un programme. Le programme doit d'abord demander la page, puis la comprendre. Comprendre une page web, pour une machine, c'est analyser son code HTML. Le HTML est un langage de balises qui structure le contenu. Une balise titre est entourée de <h1>, un paragraphe de <p>, et un prix pourrait être dans un élément <span class="prix">29,99 €</span>. Le scraper utilise ces indices structurels pour naviguer dans le document et repérer l'information cible. Cette méthode est à la fois simple et puissante, car elle repose sur la logique inhérente à la construction des sites.
Comment faire du web scraping avec Python ? un tutoriel technique pas à pas
Python est le langage de référence pour le web scraping en raison de sa simplicité de syntaxe et de l'écosystème riche de bibliothèques dédiées. Pour débuter, vous n'avez besoin que de deux bibliothèques principales. Installez-les via pip avec la commande pip install requests beautifulsoup4. Requests gère la communication HTTP, c'est-à-dire le téléchargement des pages. BeautifulSoup se charge de l'analyse syntaxique du HTML, permettant de naviguer dans l'arborescence des balises et d'extraire les données.
Voici le squelette d'un script basique de web scraping. Nous allons le détailler ligne par ligne.
python
import requests
from bs4 import BeautifulSoup
url = 'https://exemple.com'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
titres = soup.find_all('h2', class_='titre-article')
for titre in titres:
print(titre.text.strip())La première ligne importe la bibliothèque requests. La seconde importe BeautifulSoup. Nous définissons ensuite l'URL cible. La définition des en-têtes HTTP, notamment du User-Agent, est cruciale. Certains sites bloquent les requêtes qui ne viennent pas d'un navigateur reconnu. L'utilisation d'un User-Agent standard comme celui de Mozilla Firefox permet de contourner cette première ligne de défense. La fonction requests.get() envoie la requête et stocke la réponse dans l'objet response. Son attribut .text contient le code HTML de la page.
Nous passons ce HTML à BeautifulSoup en spécifiant le parser à utiliser, ici html.parser. L'objet soup qui en résulte est une représentation structurée de la page sur laquelle nous pouvons effectuer des recherches. La méthode find_all() est l'outil principal d'extraction. Elle retourne une liste de tous les éléments correspondant aux critères. Ici, nous cherchons toutes les balises <h2> dont la classe CSS est titre-article. Nous parcourons ensuite cette liste avec une boucle for et affichons le texte de chaque titre après l'avoir nettoyé des espaces superflus avec .strip().
La sélection des éléments est la compétence centrale. Pour la maîtriser, vous devez inspecter le code source des pages que vous ciblez. Ouvrez les outils de développement de votre navigateur avec F12. Utilisez l'outil d'inspection pour cliquer sur l'élément dont vous voulez extraire la donnée. Le navigateur vous montrera la balise HTML exacte, ses classes et ses identifiants. Vous pouvez utiliser des sélecteurs CSS plus puissants avec BeautifulSoup via la méthode select(). Par exemple, soup.select('div.produit > a.lien-principal') sélectionnera tous les liens de classe lien-principal situés directement dans un div de classe produit.
La gestion de la pagination est un challenge courant. Un site liste ses produits sur plusieurs pages. Votre script doit être capable de passer de l'une à l'autre automatiquement. La stratégie consiste souvent à analyser le lien "Suivant" présent en bas de page. Vous pouvez mettre votre code d'extraction dans une boucle while qui continue tant qu'un tel lien existe. À chaque itération, vous suivez ce lien, extrayez les données de la nouvelle page, puis recherchez à nouveau le lien "Suivant". Il est impératif d'ajouter des délais entre les requêtes avec time.sleep(2) par exemple. Cela réduit la charge sur le serveur cible et diminue les risques d'être bloqué pour requêtes trop agressives.
Pour les sites dynamiques qui chargent leur contenu avec JavaScript, Requests et BeautifulSoup ne suffisent plus. Elles ne voient que le HTML initial, sans le code exécuté par le navigateur. Dans ce cas, il faut utiliser des outils comme Selenium ou Playwright. Ils pilotent un vrai navigateur web, permettent d'attendre le chargement des éléments, de cliquer sur des boutons et d'exécuter du JavaScript. L'extraction se fait ensuite de manière similaire. Ces outils sont plus lourds mais essentiels pour une grande partie du web moderne.
L'export des données est la finalité. La bibliothèque Pandas est parfaite pour cela. Vous pouvez stocker vos données extraites dans une liste de dictionnaires, puis créer un DataFrame Pandas et l'exporter en CSV, Excel ou JSON.
python
import pandas as pd
data = []
for element in elements_extraits:
data.append({'nom': element.nom, 'prix': element.prix})
df = pd.DataFrame(data)
df.to_csv('donnees.csv', index=False, encoding='utf-8-sig')Commencez par vous entraîner sur des sites simples et prévus pour cela, comme les pages de Wikipedia. Évitez de scraper des sites commerciaux sans réfléchir aux conditions d'utilisation. Testez vos scripts à petite échelle avant de les lancer sur des milliers de pages. La robustesse d'un scraper vient de sa capacité à gérer les erreurs. Utilisez des blocs try...except pour gérer les timeouts, les éléments manquants ou les changements de structure.
Outils populaires pour le web scraping : du no-code aux frameworks d'entreprise
Le paysage des outils de web scraping est vaste, allant des solutions graphiques sans code aux frameworks complexes pour ingénieurs. Le choix dépend de vos compétences techniques, du volume de données, de la complexité des sites cibles et de votre budget.
Pour les débutants et les projets rapides, les outils no-code sont une excellente porte d'entrée. Octoparse et ParseHub proposent une interface visuelle de type glisser-déposer. Vous naviguez sur le site dans un navigateur intégré et cliquez sur les éléments à extraire. L'outil apprend le motif et peut le reproduire sur plusieurs pages. Ces solutions gèrent souvent le JavaScript, la pagination et l'export. Leur principal avantage est la rapidité de mise en route, sans écrire une ligne de code. L'inconvénient majeur est leur limite en volume pour les versions gratuites et leur manque de flexibilité pour des scénarios complexes. Ils sont parfaits pour des projets ponctuels de veille ou pour des équipes commerciales ou marketing.
Du côté des solutions par code, Python reste le roi. Pour des projets plus sérieux et personnalisables, les frameworks comme Scrapy sont incontournables. Scrapy n'est pas qu'une bibliothèque, c'est un framework complet conçu spécifiquement pour le web scraping à grande échelle. Il gère nativement la concurrence pour envoyer plusieurs requêtes en parallèle, un système de pipeline pour traiter les données à la volée, des middlewares pour gérer les proxies et les user-agents, et une architecture robuste. Sa courbe d'apprentissage est plus raide que BeautifulSoup, mais la productivité gagnée sur des projets d'envergure est immense. Il est particulièrement adapté au crawling, c'est-à-dire à la navigation systématique à travers de nombreux liens et domaines.
Pour le JavaScript, Puppeteer et Playwright sont les outils dominants pour le scraping de sites dynamiques. Puppeteer, développé par l'équipe Chrome, et son successeur Playwright, de Microsoft, qui supporte Chrome, Firefox et WebKit, permettent un contrôle très fin d'un navigateheadless. Ils peuvent générer des captures d'écran, simuler des interactions au clavier et à la souris, et exécuter n'importe quel code JavaScript sur la page. Ils sont indispensables pour scraper des applications web modernes construites avec React, Vue.js ou Angular. Leur inconvénient est leur consommation de ressources, car ils nécessitent l'exécution d'un moteur de navigateur complet.
Les services API comme ScrapingBee ou ScraperAPI offrent une troisième voie. Vous leur envoyez l'URL à scraper et ils vous retournent le HTML, en gérant à votre place tous les problèmes techniques : rotation de proxies pour éviter les IP bannies, rendu JavaScript, gestion des CAPTCHAs, respect de robots.txt. Ces services sont payants, généralement à la requête, mais ils externalisent la complexité opérationnelle. Ils sont idéaux pour les entreprises qui ont besoin de données fiables sans vouloir maintenir une infrastructure de scraping interne.
Les extensions navigateur comme Web Scraper.io se placent entre le no-code et le code. C'est une extension Chrome qui permet de définir des sélecteurs visuellement et de créer des plans de navigation. Les données sont extraites localement dans votre navigateur puis exportables. C'est très pratique pour des extractions légères et rapides, mais peu adapté à l'automatisation et aux volumes importants.
Le tableau suivant résume les choix possibles :
Catégorie Outil Avantages Inconvénients Prix
No-code Octoparse Interface drag-and-drop, support JS, rapide Limité en scale, gratuit freemium Freemium
No-code ParseHub Cloud, point-and-click, puissant Courbe d'apprentissage, coût à l'échelle Freemium
Code (Python) Scrapy Scalable, architecture solide, idéal crawling Complexe pour débutants Gratuit
Code (JS) Playwright Multi-navigateurs, interactions réalistes Consommation ressources, plus complexe Gratuit
API Service ScrapingBee Gère proxies/JS/CAPTCHAs, simple d'usage Coût par requête, dépendance externe Payant
Extension WebScraper.io Intégré à Chrome, très simple Manuel, pas pour volumes ou automatisation FreemiumAvant de choisir, consultez toujours le fichier robots.txt du site cible, accessible à l'adresse https://nomdusite.com/robots.txt. Ce fichier indique les parties du site que les propriétaires autorisent ou interdisent explicitement aux robots d'explorer. Le respect de robots.txt est une première marque d'éthique et peut vous éviter des ennuis juridiques. Cependant, notez que ce n'est pas un cadre légal contraignant en soi, mais une indication des souhaits du webmaster.
Légalité du web scraping en France et en Europe : cadre juridique et bonnes pratiques
La question juridique est probablement la plus critique et la plus complexe autour du web scraping. Une idée fausse très répandue est que le web scraping est illégal. En réalité, dans sa forme la plus basique, il ne l'est pas intrinsèquement en Europe. L'extraction de données publiquement accessibles sur internet est, en principe, licite. Le droit français et européen reconnaît une certaine liberté d'exploitation des informations disponibles publiquement, notamment à des fins de recherche, d'innovation ou d'analyse.
La base légale française se trouve notamment dans le Code de la propriété intellectuelle, article L.342-3. Il stipule que la base de données constituée par un site web peut être protégée par un droit sui generis si son obtention, sa vérification ou sa présentation représente un investissement financier, matériel ou humain substantiel. Toutefois, l'extraction d'une partie non substantielle de son contenu, souvent à des fins privées ou de recherche, est généralement autorisée. C'est une zone grise où la notion de "partie substantielle" est subjective et s'apprécie au cas par cas.
Le premier risque majeur provient de la violation des Conditions Générales d'Utilisation. Beaucoup de sites incluent une clause dans leurs CGU interdisant explicitement le scraping, l'automatisation ou l'utilisation de robots. En utilisant le site, vous acceptez contractuellement ces conditions. Les techniques de contournement de ces interdictions, comme l'usurpation d'identité via le User-Agent ou l'utilisation de proxies pour masquer son IP, peuvent aggraver la situation en constituant potentiellement un accès frauduleux à un système informatique, réprimé par l'article 323-1 du Code pénal, avec des peines pouvant aller jusqu'à cinq ans d'emprisonnement et 300 000 euros d'amende.
Le deuxième risque, et le plus lourd de conséquences aujourd'hui, est lié au Règlement Général sur la Protection des Données. Le RGPD s'applique dès lors que vous traitez des données à caractère personnel, c'est-à-dire toute information se rapportant à une personne physique identifiée ou identifiable. Un nom, une adresse email, un numéro de téléphone, mais aussi une adresse IP ou un identifiant de cookie sont des données personnelles. Si votre projet de scraping implique de collecter de telles données, vous devez vous conformer au RGPD.
Cela signifie que vous devez identifier une base légale pour votre traitement. La base la plus couramment invoquée pour le scraping à des fins professionnelles est l'intérêt légitime. Vous devez démontrer que votre intérêt légitime (par exemple, une analyse de marché) n'est pas surpassé par les droits et libertés de la personne concernée. Vous devez également informer les personnes, via une politique de confidentialité, que vous collectez leurs données et comment. En pratique, pour le scraping de profils publics LinkedIn à grande échelle, la CNIL a déjà sanctionné des entreprises, comme dans une décision de 2020 avec une amende de 20 000 euros. La jurisprudence européenne, avec l'arrêt "hiQ Labs c. LinkedIn", a cependant reconnu un certain droit au scraping de données publiques, même contre l'avis du site, au nom de la libre concurrence et de l'intérêt public, mais ce cadre évolue constamment.
Les bonnes pratiques sont donc impératives. Premièrement, limitez le taux de requêtes pour ne pas surcharger les serveurs. Utilisez des délais entre chaque requête. Deuxièmement, identifiez-vous clairement dans votre User-Agent avec une adresse email de contact. Troisièmement, ne collectez que le strict nécessaire et anonymisez les données personnelles dès que possible. Quatrièmement, respectez le champ robots.txt. Enfin, pour tout projet commercial d'envergure, consultez un juriste spécialisé en droit du numérique et en propriété intellectuelle. Cette consultation est un investissement nécessaire pour sécuriser vos activités, surtout si vous envisagez de créer une base de données à des fins de prosopographie ou de pricing dynamique.
Applications pratiques du web scraping : cas concrets sectoriels et création de valeur
Le web scraping n'est pas une fin en soi, c'est un moyen au service de la stratégie et de l'opérationnel. Sa valeur se mesure à l'impact qu'il a sur les processus métier, la prise de décision et la rentabilité. Examinons des applications concrètes dans différents secteurs.
Dans l'e-commerce et la vente au détail, le web scraping est un pilier de la stratégie de pricing dynamique. Des entreprises comme camelcamelcamel scannent en permanence les prix de millions de produits sur Amazon pour tracer leur historique et alerter sur les baisses. Les grands retailers utilisent des scrapers maison pour surveiller les prix de leurs concurrents directs, plusieurs fois par jour. Cette intelligence permet d'ajuster ses propres prix en temps quasi réel pour rester compétitif sans sacrifier la marge. On estime qu'une stratégie de pricing optimisée par le scraping peut augmenter les marges de 5 à 20%. Au-delà du prix, on peut scraper les descriptions produits, les images, les avis clients et le stock pour enrichir son propre catalogue ou analyser la satisfaction client.
Dans le domaine du recrutement et des ressources humaines, le scraping transforme la chasse de talents. Les plateformes comme Indeed, LinkedIn et les sites carrières des entreprises regorgent de données structurées sur les offres d'emploi : intitulé du poste, compétences requises, localisation, fourchette salariale parfois. Un scraper peut agréger ces offres par métier, par région, par niveau d'expérience. Pour un cabinet de recrutement, cela permet de cartographier le marché, d'identifier les compétences les plus demandées et de conseiller efficacement ses candidats. Pour une grande entreprise, cela permet une analyse de la concurrence sur les packages de rémunération et les avantages.
L'industrie du voyage est probablement l'une des plus transformées par ces techniques. Les agrégateurs comme Kayak, Skyscanner ou Google Flights fonctionnent essentiellement grâce à des partenariats et du scraping avancé pour collecter les prix des billets d'avion, des chambres d'hôtel et des locations de voiture depuis des centaines de sources. Des outils plus spécialisés permettent aux agences de voyage de créer des alertes personnalisées pour leurs clients ou d'analyser les tendances tarifaires sur des destinations précises.
Dans les médias et le sport, le scraping permet de créer des agrégateurs d'actualités ou de scores. Des sites comme Transfermarkt, référence du football, construisent leur base de données colossale sur les joueurs, les transferts et les valeurs de marché grâce à une collecte systématique d'informations publiques. Les sociétés de trading sportif utilisent le scraping en temps réel sur les sites officiels pour alimenter leurs modèles de prédiction.
Pour les systèmes d'information d'entreprise comme les ERP, le web scraping est un levier puissant d'automatisation et d'enrichissement. Prenons l'exemple d'Odoo, populaire en Bretagne et ailleurs. Une entreprise manufacturière peut scraper les catalogues de ses fournisseurs pour mettre à jour automatiquement les prix et les références dans son ERP. Une entreprise de distribution peut enrichir sa base clients en collectant des informations publiques sur les sites de ses prospects. Une entreprise agroalimentaire peut surveiller les prix des matières premières sur les marchés en ligne. L'intégration se fait via les APIs Python d'Odoo, créant un flux de données entrant automatisé qui élimine les saisies manuelles, sources d'erreur et de perte de temps.
La valeur finale est toujours la même. Le web scraping automatise la veille, transforme des données brutes et éparses en information actionnable, et permet une prise de décision plus rapide et plus éclairée. Il réduit les coûts opérationnels et peut générer des gains de revenus significatifs. C'est un multiplicateur de force pour les entreprises qui savent l'utiliser de manière éthique et efficace.
L'avenir du web scraping avec l'intelligence artificielle : des agents autonomes et auto-adaptatifs
L'arrivée de l'intelligence artificielle générative et des grands modèles de langage est en train de provoquer une disruption majeure dans le domaine du web scraping. La limite traditionnelle était la rigidité du code. Un scraper écrit pour une page spécifique casse dès que la structure HTML change. La maintenance était coûteuse. L'IA change la donne en introduisant la compréhension sémantique et l'adaptabilité.
Le concept émergent est celui du MCP, ou Model Context Protocol. Il s'agit de fournir à un grand modèle de langage, comme GPT-4, le contexte d'une page web et de lui demander d'extraire des informations via des instructions en langage naturel. Au lieu d'écrire du code avec des sélecteurs CSS complexes comme div.product-price > span.value, vous donnez un prompt : "Extrais tous les prix des produits et leurs noms sur cette page." Le modèle comprend la sémantique de la page, identifie ce qu'est un prix et un nom de produit, et retourne les données structurées. Des outils comme ScrapeGraphAI incarnent cette approche. Ils utilisent des LLMs pour interpréter la page, générer le code d'extraction adapté et même s'ajuster automatiquement à de légers changements de mise en page.
Les tendances pour 2026 et au-delà se dessinent clairement. Nous allons voir l'émergence d'agents de scraping autonomes et self-healing. Ces agents recevront une mission en langage naturel, comme "Surveille l'évolution du prix de ce modèle de vélo sur ces 5 sites e-commerce chaque jour et envoie-moi un rapport hebdomadaire." L'agent planifiera lui-même les exécutions, détectera les changements de structure du site, ajustera sa stratégie d'extraction et vous alertera en cas de problème. La maintenance humaine sera réduite au minimum.
Les services cloud évoluent également. Les APIs de scraping traditionnelles vont intégrer des modules IA pour le rendu JavaScript, la résolution de CAPTCHAs complexes via la vision par ordinateur, et la rotation intelligente des proxies pour imiter des comportements humains réels et contourner les systèmes de détection de plus en plus sophistiqués.
La dimension éthique et régulatoire sera aussi transformée par l'IA. Nous pourrions voir l'apparition de fichiers robots.txt enrichis, interprétables par les IA, détaillant non seulement ce qui est interdit mais aussi les conditions d'usage des données. L'EU AI Act, le règlement européen sur l'intelligence artificielle, classera probablement certains systèmes de scraping IA à grande échelle et intrusifs comme à haut risque, imposant des obligations de transparence et de conformité renforcées.
Le défi majeur sera la course aux armements entre les scrapers IA et les systèmes anti-bot IA. Les sites chercheront à protéger leurs données avec des défenses adaptatives qui détectent les patterns non-humains, même sophistiqués. L'équilibre entre l'accès légitime à l'information publique et la protection de la propriété intellectuelle et de la vie privée se jouera sur ce terrain technologique. Pour l'utilisateur final, cette évolution signifie une démocratisation encore plus grande. La barrière technique du code disparaît. L'extraction de données web deviendra une compétence accessible à tout professionnel sachant formuler clairement son besoin.
Google Disco et Perplexity Comet : Les navigateurs agentiques, des game-changers no-code
Deux produits récents illustrent parfaitement la fusion entre le web scraping, la navigation et l'intelligence artificielle générative. Ils préfigurent l'avenir de l'interaction avec le web pour la collecte d'information.
Google Disco est un projet expérimental issu de Google Labs, révélé fin 2025. Il s'agit d'un navigateur, ou d'une extension de navigateur, propulsé par Gemini, le modèle d'IA de Google. Son principe révolutionnaire est simple. Vous ouvrez plusieurs onglets sur des sujets connexes, par exemple des pages de comparateurs de vols, des blogs de voyage et des sites météorologiques pour une destination. Disco analyse le contenu de tous ces onglets ouverts simultanément. Ensuite, via une interface conversationnelle, il vous propose de générer des "GenTabs". Ces GenTabs sont des tableaux de bord personnalisés qui extraient et croisent automatiquement les données de vos onglets sources. Par exemple, un GenTab "Planificateur de voyage" pourrait extraire les prix des billets d'un onglet, les avis sur les hôtels d'un autre et les prévisions météo d'un troisième, pour les présenter dans un seul tableau synthétique, exportable. L'implication est énorme. L'utilisateur n'a plus besoin de savoir quoi scraper ni comment. Il navigue normalement, et l'IA déduit son intention et lui propose des synthèses actionnables. L'intégration potentielle dans Chrome en ferait un outil d'une puissance inédite pour les chercheurs, les analystes et les consultants.
Perplexity Comet, de son côté, est présenté comme un "navigateur agentique". C'est une application à part entière qui repense la navigation. Vous ne surfez plus, vous donnez une mission. Le prompt est roi. Vous tapez : "Scrape les 10 premiers t-shirts pour homme sur Amazon, avec leur prix, leur note moyenne et le nombre d'avis, et exporte-les dans un fichier CSV." Comet lance alors un navigateheadless, exécute la recherche sur Amazon, parcourt les pages, extrait les données demandées, les structure et télécharge le fichier CSV sur votre ordinateur. Tout cela sans que vous n'ayez jamais vu la page Amazon. Il gère la navigation, le JavaScript, la pagination, les pop-ups. La version Pro, accessible via un système de referral, offre plus de puissance et de requêtes. Pour un consultant qui doit régulièrement faire de la veille produit ou du lead generation, c'est un gain de temps phénoménal. Pour l'intégration dans un ERP comme Odoo, on imagine très bien des agents Comet programmés pour surveiller quotidiennement les prix de fournisseurs ou les fiches produits de concurrents, et mettre à jour automatiquement les bases de données internes via API.
Ces outils ne sont pas de simples améliorations. Ce sont des changements de paradigme. Ils démocratisent l'accès à la puissance du web scraping en le rendant totalement no-code et conversationnel. Le métier évolue du développement de scripts techniques vers la conception de prompts précis et la gestion de workflows d'agents intelligents. Pour les entreprises, en particulier les PME qui n'ont pas de département technique dédié, c'est une opportunité immense d'automatiser leur veille et d'enrichir leurs systèmes d'information à un coût marginal très faible. Le rôle du consultant ou de l'intégrateur devient alors d'identifier les flux de données critiques, de concevoir les prompts et les workflows adaptés, et d'assurer l'intégration fluide avec les outils métier comme Odoo.
Bonnes pratiques, perspectives et conclusion pour votre stratégie
Pour conclure ce guide pédagogique, synthétisons les bonnes pratiques absolues et les perspectives stratégiques, en particulier pour un contexte d'entreprise utilisant des ERP comme Odoo.
Sur le plan éthique et opérationnel, adoptez toujours une approche responsable. Sollicitez le consentement quand c'est possible, surtout pour les données personnelles. Implémentez un rate-limiting strict. Laissez toujours une trace de contact dans vos requêtes. Ne scrapez que ce dont vous avez besoin. Vérifiez la licéité de votre projet avec un expert juridique. Ces précautions ne sont pas des freins, ce sont les fondations d'une pratique durable qui protège votre entreprise de risques majeurs.
Sur le plan technique, adoptez une architecture hybride IA/code. Utilisez les nouveaux outils agentiques comme Google Disco ou Perplexity Comet pour le prototypage rapide, l'exploration et les projets légers. Pour les pipelines de production critiques, volumineux et nécessitant une fiabilité absolue, maintenez une base de code traditionnelle avec Scrapy ou Playwright. L'IA peut alors servir d'outil de résilience, capable de réparer ou de réécrire des parties du code si une structure de site change brutalement.
Concrètement, pour vous, entreprise basée en Bretagne utilisant Odoo, voici un plan d'action. Identifiez les données externes qui auraient le plus d'impact sur votre ERP. Est-ce le prix des matières premières agricoles ou textile que vous achetez ? Est-ce le catalogue produit de vos concurrents pour votre propre boutique en ligne ? Est-ce la liste des entreprises de votre secteur dans votre région pour votre force de vente ? Priorisez une source.
Commencez par un prototype avec un outil no-code IA. Testez la faisabilité de l'extraction. Puis, pour une automatisation robuste, développez un script Python qui scrape ces données périodiquement. Structurez-les dans un DataFrame Pandas. Enfin, utilisez l'API REST ou XML-RPC d'Odoo pour pousser ces données directement dans les modules concernés. Vous pouvez créer des produits, mettre à jour des fiches fournisseurs, ajuster des listes de prix, tout cela sans intervention manuelle.
La clé réside dans la structure et la clarté de votre démarche. Chaque section de votre projet doit répondre à une seule intention. Avant de coder, définissez précisément la question métier. L'outil technique n'est qu'une réponse. En adoptant cette discipline et en exploitant la puissance conjuguée du scraping traditionnel et de l'IA générative, vous transformez le web, océan de données désorganisées, en un actif stratégique structuré et dynamique pour votre entreprise. L'avenir appartient à ceux qui savent non pas seulement collecter des données, mais orchestrer intelligemment leur flux pour éclairer la décision et automatiser l'action.
- Définissez d’abord l’objectif métier, puis choisissez l’outil et l’architecture.
- Prototypage no-code IA pour valider vite, pipeline code pour industrialiser.
- Conformité et éthique : limitation du débit, minimisation des données, vigilance RGPD et CGU.